How to Easily Import Data from Word Documents into Your App: A Complete Guide
Programmatically extract text data from Word files

Passionate developer and software crafter with a passion for problem-solving. Always learning and growing in the field.
Currently looking for a job or freelance gig. Need a software consultant? I am your guy!
With experience in websites, applications, and cloud services, I can provide top-notch solutions for your business needs. Let's work together to take your tech game to the next level. Contact me today for part-time consulting opportunities
Introduction
Recently, I was involved in data migration for a client. The data mainly consists of exam questions and their explanations. The data was structured in (.xlsx) format but there was one problem with the content of the data.
Some of the questions included mathematical equations which was a problem for us as it could not be saved as a text format in the cell of the Excel document. Usually, the equations are added in shape format which was difficult to read programmatically.
Some of the equations were very complex e.g.
$$\displaystyle P_\lambda = \frac{2 \pi h c^2}{\lambda^5 \left(e^{\left(\frac{h c}{\lambda k T}\right)} - 1\right)}$$
So, instead of saving the mathematical questions in Excel format, they used DOC format which was way easy as compared to adding equations in an Excel format.
There were around 1000 mathematical questions that included equations in it. One way was to copy/paste manually and the other way was to do it programmatically.
Being a software developer I preferred the second way and you will find that in the next few minutes how I was able to import the data from a Word document, but before that, we should understand the importance of importing and exporting data.
Why Import/export data?
Import and export of data play a significant role in today's world. Almost all businesses require a set of data to formulate growth strategies and enhance operations, analysis, and decision-making.
The key benefits of importing and exporting data are
Enhanced decision making
Data sharing and Collaboration
Data Visualization and Reporting
Accuracy and Reliability
and many more...
The most common formats to import data are CSV, XML, or JSON as they ensure compatibility across different systems and platforms.
However today we will discuss a different format i.e. Doc files or Word Documents which is mainly a word processing document format. DOC files are used to store data such as formatted text, images, tables, and charts. The most common DOC formats widely used are .doc or .docx and they are merely not just a text file but larger than that.
Setting up the environment
We will be using a Python library python-docx to read and write DOC files. This library works well with the .docx format. If you are having .doc format, you might first need to convert them to .docx formats either by using Microsoft Word or some conversion tool.
One good thing that was done was the Doc file was formatted properly since there were 1000 questions to be imported, and each question with its details was added to a separate table. This not only helped organize the document but also did help in importing the document.
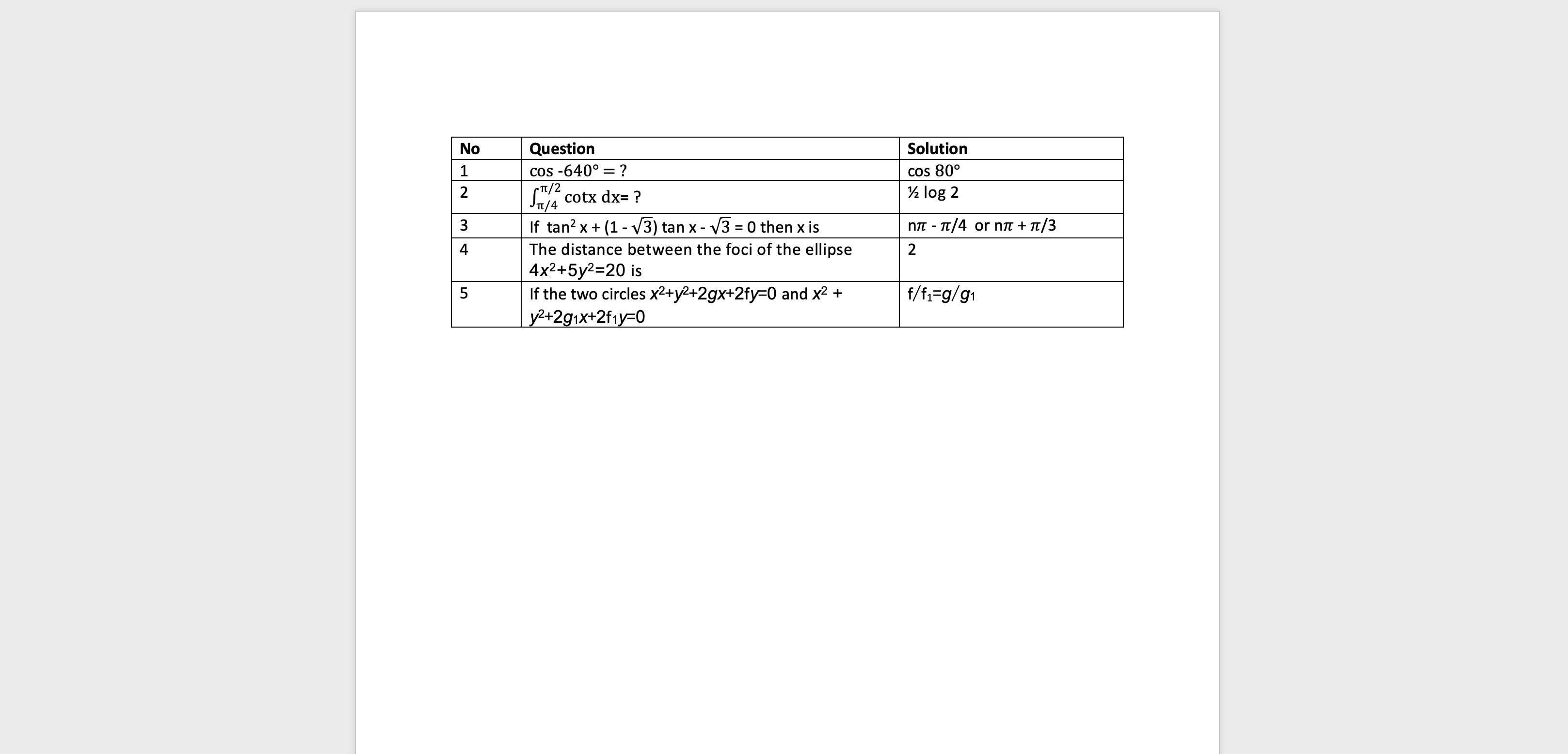
Below is the sample image of the Word document which was used to be imported.
Install python-docx
python-docx is a library for reading, creating, and updating (.docx) files. Let's first install the library.
pip install python-docx
The whole task of extracting data from a Word document was to
Read the Document i.e. use the library
python-docxto extract text from the document.Parse the extracted text into structured JSON
Generate JSON object.
Extracting Data
Read the Document
Below is an example of how to open a document file and read its content.
import docx
# Load the document
doc = docx.Document('sample.docx')
Structure of the Document
The basic structure of the document was in a tabular format, and it looks something like below.
| No | Question | Solution |
| 1 | cos -640° =? | cos 80° |
| 2 | \= ? | ½ log 2 |
| 3 | If tan2 x + (1 - ) tan x - = 0 then x is | n - /4 or n + /3 |
| 4 | The distance between the foci of the ellipse 4x2+5y2\=20 is | 2 |
| 5 | If the two circles x2+y2+2gx+2fy\=0 and x2 + y2+2g1x+2f1y\=0 | f/f1\=g/g1 |
Now based on the above structure we can easily identify that the first row is the header row and the rest of the rows are the data rows. In the next part, we will parse the data based on the tabular format.
Parse the Document
Let's parse the data based on the structure. Since our data is stored in tabular format, it is good to make sure that the count of tables in the document is 1 and not more than that.
# Count the No of Tables in the document.
table_count = len(doc.tables)
print("Number of tables in the document:", table_count)
In case it is more than 1 then you need to make sure about the structure of the table and whether it is to be extracted or not.
Let's extract the questions from the table, assuming we have multiple tables and the table to be used is at the index 0.
# Extract questions from the document
questions = extract_questions_from_table(doc)
print(questions)
def extract_questions_from_table(doc):
return [
{
"index": row.cells[0].text,
"question": row.cells[1].text,
"solution": row.cells[2].text,
}
for row in doc.tables[0].rows[1:]
]
In the above code, we are using nested list comprehension. We can extract the data from the table. The outer loop for the table in doc.tables iterates over each table in the document, and the inner loop for row in table.rows[1:] iterates over each row in the current table, starting from the second row.
For each row, a dictionary is created with the text from the first three cells and added to the list.
The output should be something like this
[{'index': '1', 'question': 'cos -640° = ?', 'solution': 'cos 80°'},
{'index': '2', 'question': '= ?', 'solution': '½ log 2'},
{'index': '3', 'question': 'If tan2 x + (1 - ) tan x - = 0 then x is', 'solution': 'n - /4 or n + /3'},
{'index': '4', 'question': 'The distance between the foci of the ellipse 4x2+5y2=20 is', 'solution': '2'},
{'index': '5', 'question': 'If the two circles x2+y2+2gx+2fy=0 and x2 + y2+2g1x+2f1y=0', 'solution': 'f/f1=g/g1'}]
Generate the JSON from extracted data
Next, we can create the JSON format from the output we received earlier, by using the below code. Make sure the native module json is imported initially.
# Generate JSON based on the output response.
import json
def generate_json(questions, filename):
questionnaires = []
for question in questions:
questionnaire = {
"index": question["index"],
"title": question["question"],
"explanation": question["solution"],
}
questionnaires.append(questionnaire)
with open(filename, "w") as f:
json.dump(questionnaires, f, indent=4)
# Generate JSON File
jsonfile = generate_json(questions, "sample.json")
And voilà! We have successfully extracted the data from a Word document into JSON format. It is important to note that the more structured the data is, the easier it will be to extract.
The above data can be easily stored in any type of persistent storage, such as RDBMS or NoSQL databases.
Conclusion
That's it for today, and congratulations to everyone who has followed this blog! You've successfully imported data from a structured Word document into JSON format. Awesome job! 🎉
I hope you have learned something new, just as I did. If you enjoyed this article, please like and share it. Also, follow me to read more exciting articles. You can check out my social links here.